

I recently joined the engineering team at Chroma, an open-source AI application database. I believe Chroma will become an cornerstone tool for AI-powered applications.
As companies adopt large language models, they face challenges integrating their unique product details and customer data into AI systems. Chroma is a purpose-built database that stores information in a way AI models can access. Today, the most common application is retrieval-augmented generation (RAG). As AI moves toward more autonomous workflows, search will become a tool that AI agents query independently while performing tasks.
Multiple vector database products exist in the market, and they often compete based on database size. Chroma differentiates itself with an important insight: most developers do not need a large vector database, but instead require many small databases.
Most software services today are multi-tenant, meaning they store information for multiple customers in a single database. For example, in my project Booklet, different communities are co-located in the same database. And, the original implementation of AI and vector search on Booklet utilized one database.

Traditional SQL databases are efficient at filtering. You can quickly retrieve all posts for a specific community, even with millions of customers. However, vector search operates differently. It is spatial and less adept at filtering as applications scale.
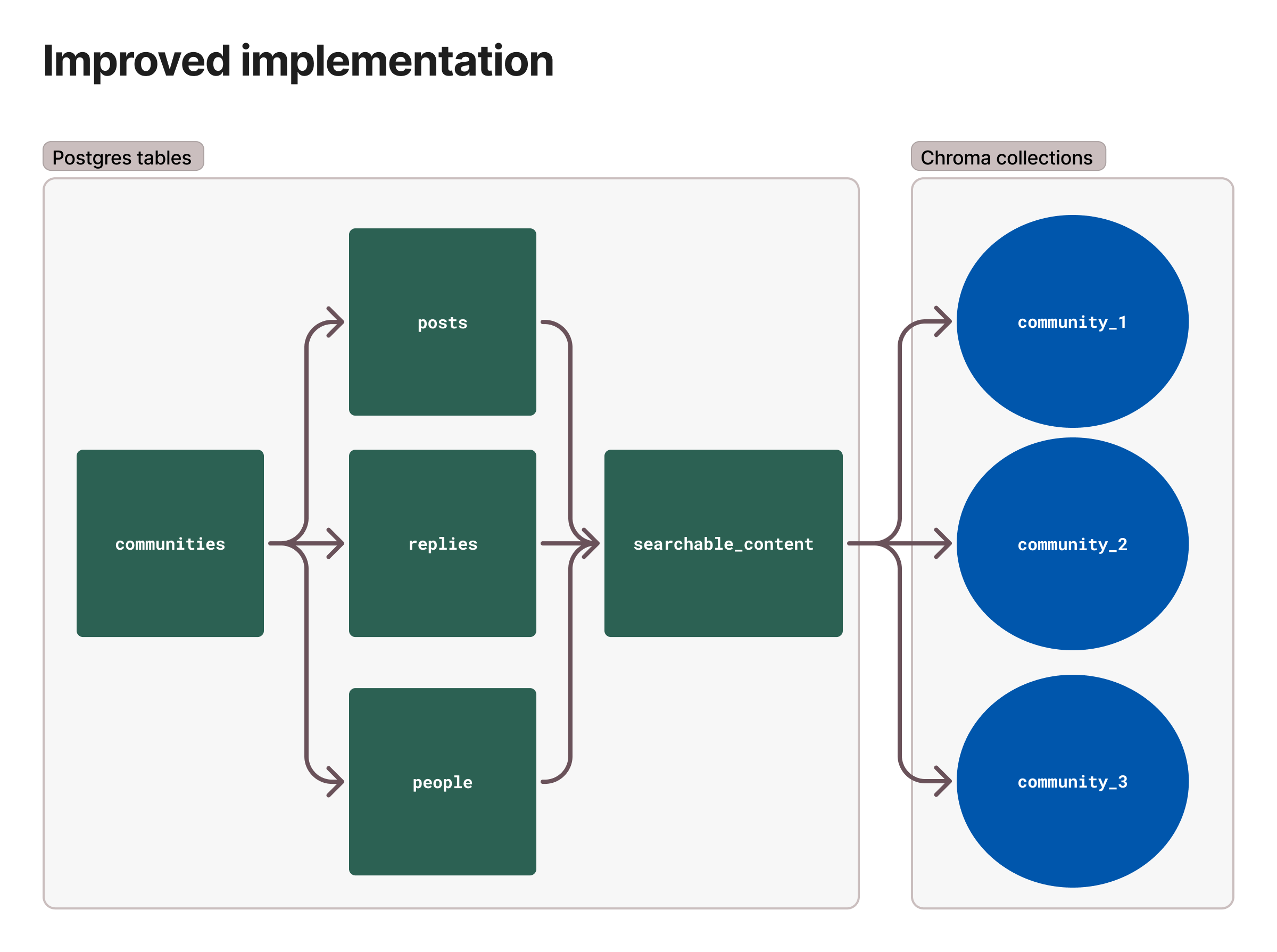
The reality is that software products typically isolate customer data. In Booklet's search, users can only access data within their community. This creates an opportunity to shard customer data into separate indexes. By creating many small vector databases, performance remains high as the application grows.
When I migrated Booklet's search and AI to Hosted Chroma, I established a separate collection for each community. While splitting data in traditional SQL databases is often discouraged, vector databases benefit from distributed indexing. Chroma excels at making data splitting straightforward for developers, enabling more scalable AI systems.
Chroma appealed to me immediately because it's a developer-focused tool. Throughout my career, from founding Moonlight to building various developer platforms, I've been drawn to tools that empower technical teams. And, the company matched all of the criteria I outlined in my recent reflection on finding my professional path - it's an in-person culture of ambitious and smart people working on AI in San Francisco with a commitment to design and practical problem-solving. Plus, it's growing quickly - Chroma has gained significant open-source traction, with millions of downloads and a growing community.
We're amid the installation phase of AI technology - we have new tools, but we're only just beginning to think about how new products can natively leverage this technology - which means that the products we see today are merely the first draft of a much larger story. It's an exciting time in history, and I'm motivated to be working in the middle of it.
If you are working to incorporate AI into your application, come try Chroma.


